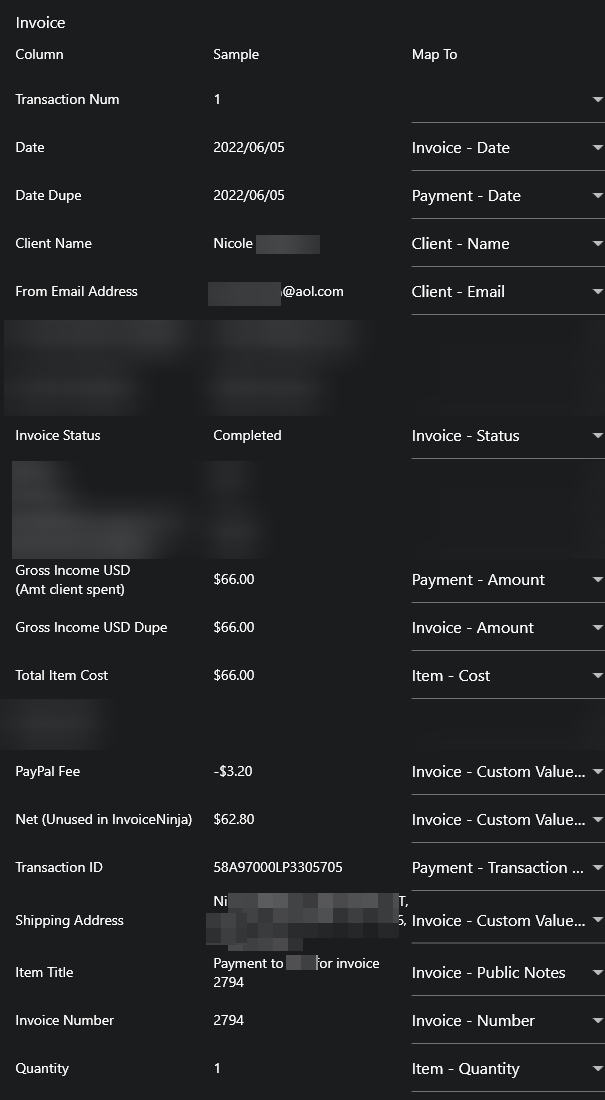
I imported customers (name, email, all address fields including phone, currency, 1 custom)
I imported payments (all fields except user; used email for client since it’s a unique identifier)
This wiped all my client data except vtd (new) and email. Name is now duped by email.
Why would importing payments nuke my client fields? I tried reimporting customers to fill back in the customer data, but I had errors that these clients already existed (instead of updating the info).
Edit: If I reimport my customer list and ONLY import name+email, would this be fixed? Or would I get dupes?
Earlier, I tried adding customers last and it’d say the customers already exist (instead of update the info).
EDIT: I was able to reimport again (when is strange – I still have an email from last time when it wouldn’t let me. Perhaps I used the website instead that time?). However, I encountered a new bug where it’d just dupe all my customers,ignoring the unique email id.
Hmm, so it’s a bug - the import was very destructive. I was able to repro it multiple times depending on the order I imported things. I’ll make a few foobar csv’s soon with a screencast.
…but when I tried to reimport name - addresses - phone (contact+client), it imported dupes. I thought emails were a unique key? Darn, now I have to purge the entire db for some more trial+error.
I wish there were some previews of what would show when this would be imported – or some override rules.
If a client is not found, a new client is created. If you’d like to provide a client.csv and payment.csv file which is overwriting an existing client we can look into it.
An idea is to show 100 rows at a time since I only have 800 dupes. It would only take me 8 times to wipe them.
I’m looking for advanced search settings, but can’t seem to find any. I only want to search for name. Since all names have email, I’d simply have to name: *@* or something like that. At 100 pages at a time, I can select them all and delete in 8 batches.