Hello,
I am working on a script to automate keeping IN up to date using git and I keep adding stuff to it as I encounter issues.
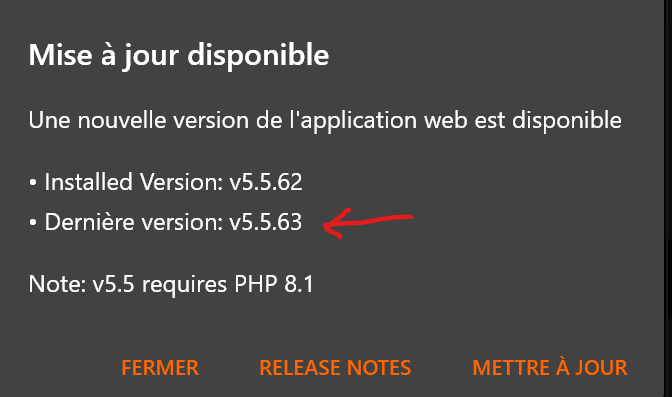
On my last run through a cron job, it did not update the app, so I ran it manually to see what happened, and when I ran git pull, I got told that a couple of files (composer.lock, composer,json) had been modified and that the process would abort. I don’t know how how that happened exactly, but I ran the git checkout composer.json composer.lock command and then I could procede with the pull.
That made me think about automating dealing with modified files by backing them up instead of deleting them, but it was way over my competence level. I heard that GPT Chat was good at coding, so I tried it out. Wow! It’s a beast (at least compared to me), it understands exactly everything I ask and puts it into code, it modifies the code accordingly when I ask for a modification, it answers to my questions perfectly… I’m impressed. All in all it’s a work in progress (Both GPT chat and my script), but I think I’m on the right path. I’ll first start by letting GPT describe that part of the script:
Q. Can you do a recap of the whole script for now and tell me what it does in detail?
A. Sure, here’s a summary of the script:
- The script starts by using the
git status --porcelaincommand to get a machine-readable output of the status of the files in your repository.- The
grep '^[AM]'andgrep '^UU'filters the files that are in conflict and modified, theawk '{print $2}'command is used to extract the name of the file.- It then uses an if statement to check if there are any modified or conflicting files, if there are, it proceeds to the next step, if not, it skips the following steps and continues to the git pull command.
- The script then uses an if statement to check if the
gitbackupfolder already exists, if it doesn’t, the script will create it using themkdir gitbackupcommand. If the folder already exists, it will skip the mkdir statement and continue with the rest of the script.- For each file in modified_files and conflict_files, it runs the
git stash push -m "stash-conflict" $filecommand, this command saves the current changes in a new stash and the -m flag is used to provide a name to the stash.- It then runs a second loop, this time for each file in modified_files and conflict_files, using an if statement to check if the file is already in the gitbackup folder, if it is, it will add an incremental number to the file name and move it to the gitbackup folder. If the file is not in the gitbackup folder, it will move it to the gitbackup folder.
- Finally, it uses the
echocommand to send an email notification to the email address specified, informing that there were conflicts that need to be checked, theThis script is designed to be run after a
git pullcommand that is blocked by conflicts, it will backup the modified and conflicting files in thegitbackupfolder, it will add an incremental number to the file name to avoid overwriting the files, it will then send an email notification to the provided email address, informing that there were conflicts that need to be checked.Please make sure that the script is being run in the correct directory and that the path to the
/gitbackupfolder is correct, also, check that the script has the necessary permissions to create the folder and move the files, and that thegit stash,mvandPlease let me know if you have any other question or if you need any help.
Now the code:
#!/bin/bash
# check for modified and conflicting files
modified_files=($(git status --porcelain | grep '^[AM]' | awk '{print $2}'))
conflict_files=($(git status --porcelain | grep '^UU' | awk '{print $2}'))
# stash the modified and conflicting files
if [ ${#modified_files[@]} -gt 0 ] || [ ${#conflict_files[@]} -gt 0 ]; then
if [ ! -d "gitbackup" ]; then
mkdir gitbackup
fi
for file in "${modified_files[@]}" "${conflict_files[@]}"; do
git stash push -m "stash-conflict" $file
done
for file in "${modified_files[@]}" "${conflict_files[@]}"; do
if [ -f gitbackup/$file ]; then
i=1
while [ -f gitbackup/${file}_$i ]; do
let i++
done
mv gitbackup/$file gitbackup/${file}_$i
else
mv gitbackup/$file gitbackup/
fi
done
# Send email notification
echo "Conflicts found while trying to pull the changes from the remote repository" | mail -s "Conflicts found" [email protected]
else
git pull
fi
Comments are welcome!
Thanks